Facebook翻译错误导致一名建筑工人被抓
这是最近几年非常流行的一个句子,试试看能不能读懂——
“Aoccdrnig to a rscheearch at Cmabrigde Uinervtisy, it deosn’t mttaer in waht oredr the ltteers in a wrod are, the olny iprmoetnt tihng is taht the frist and lsat ltteer be at the rghit pclae.”
虽然大部分单词都是拼写错误的,但似乎并不会影响我们理解它的意思。这说明:人在理解语言时,鲁棒性是很强的,文本中即使漏掉一两个字母或者拼写错误,很多时候都不会影响人的阅读。
但对机器翻译(MT)系统来说,这些文本就几乎是不可理喻的了。甚至!一不小心还会造成恶劣的影响。雷锋网了解到,近日在以色列就有一个案例,因为机器翻译的错误,一名建筑工人在他facebook上发了条状态后,“成功”进了局子。
故事大概就是,这名建筑工人10月15日在自己的facebook上发了一条状态:“يصبحهم”(ySbHhm,阿拉伯语)并配了一张照片:

照片中他斜靠在一辆推土机上。这条状态的原意是“good morning”,但facebook的MT 却将它和“يؤذيهم”(y*bHhm)混淆了,两者只差一个字母,但后者在希伯来语中的意思却是“attack them”(雷锋网向阿语专家请教,用中文理解应为“宰了他们”)。

以色列警方此刻正监管网络来找一群称为“lone-wolf”的恐怖分子,所以立马就注意到了这条状态。
推土机+“宰了他们”(过去曾有恐怖分子用推土机进行恐怖袭击),警方怀疑这个人很有可能要进行恐怖袭击,于是立即就逮捕了他。审问几个小时后才发现原来是机器翻译的乌龙。
一、噪声对机器翻译影响有多大?
在我们的文本当中,拼写错误(或者称为噪声)是很常见的现象,而在自然语言处理的各种神经网络的训练系统(包括翻译系统)中却并没有一个明确的方案来解决这类问题。大家能够抱希望的方式就是,通过在训练数据中引入噪声来减小翻译过程中噪声带来的破坏。
但是在训练数据集中引入噪声或者不引入噪声会带来多大的影响呢?在不同的语言机器翻译训练中引入噪声结果是否一致呢?似乎目前并没有对这一问题严格的研究。
雷锋网注意到,最近来自MIT的Yonatan Belinkov和来自华盛顿大学的Yonatan Bisk就此问题在arXiv上发表了一篇有意思的论文。

论文中,他们利用多种噪声讨论了目前神经网络机器翻译的脆弱性,并提出两种增强翻译系统鲁棒性的方法:结构不变词表示和基于噪声文本的鲁棒性训练。他们发现一种基于字母卷积神经网络的charCNN模型在多种噪声中表现良好。

BLEU为机器翻译结果与人工翻译结果对比值(纵坐标应为%,作者忘记标注,下同)。可以看到随着文本中加入噪声的比例增加,机器翻译的结果快速下降。
二、模型
作者选择了三种不同的神经机器翻译(NMT)模型以做对比,分别为:
1、char2char。这是一个seq-2-seq的模型,它有一个复杂的卷积编码器、highway、循环层以及一个标准的循环解码器。细节参见Lee等人(2017)的研究。这个模型在德-英、捷克-英之间的语言对翻译上表现非常好。
2、Nematus。这也是一个seq-2-seq的模型,在去年的WMT和IWSLT上是一种较为流行的NMT工具包。
3、charCNN。作者用词表示训练了一个基于character卷积神经网络(CNN)的seq-2-seq的模型。这个模型保留了一个单词的概念,能够学习一个依赖于字符的词表示。因为它可以学习词的形态信息表示,所以这个模型在形态丰富的语言上表现非常好。
三、数据
数据集来源:作者选用了TED为IWSLT 2016准备的测试数据。
噪声来源:分为自然噪声和人工噪声。
1、自然噪声
由于上面的数据集没有带有自然噪声的平行语料库,因此作者选择了其他的可用的语料库,例如:
法语:Max&Wisniewski在2010年从Wikipedia的编辑历史中收集的“维基百科更正和解释语料库”(WiCoPaCo),在本文中仅仅提取了单词更正的数据。
德语:由RWSE 维基百科修订数据集(Zesch,2012)和MERLIN语言学习者语料库(Wisniewski et al., 2013)。
捷克语:数据来源于非母语者手动注释的散文。
2、人工噪声
作者生成人工噪声的方法有四种,分别为交换(Swap)、中间随机(Middle Random)、完全随机(Fully Random)和字母错误(Key Typo)。
交换(Swap):对一个字母个数大于4的单词,除了第一个和最后一个字母不变外,随机交换中间的任两个字母一次。
中间随机(Mid):对一个字母个数大于4的单词,除了第一个和最后一个字母不变外,随机排列中间所有的字母。
完全随机(Rand):所有单词的字母随机排列。
字母错误(Key):在单词中随机选取一个字母,用键盘中和它临近的字母替换(例如noise-noide)
四、干净文本训练翻译模型
作者首先测试了用干净(Vanilla)文本训练出的模型是否能够经受住噪声的考验。

通过上表的结果,我们可以看出所有模型在有噪声(不管是自然的还是合成的)BLEU值都会显著下降。
或许通过下面这个例子,可以更明显地感受到人类理解噪声文本的能力与机器翻译的能力有多大差别。

输入文本是乱七八糟的德语文本,但人类翻译仍然能够根据文本猜测到意思,而目前几个优秀的机器翻译模型则表现很差。
五、两种方法改进模型
1、meanChar模型
从上面的结果我们可以看到,三种NMT模型对单词的结构都很敏感。Char2char和charCNN模型在字符序列上都有卷积层用来捕获字符n-gram;Nematus模型则基于由BPE获得的sub-word单元。因此所有这些模型对字符乱置(Swap、Mid、Rand)产生的噪声都会敏感。
那么可以通过对这样的噪声添加不变性来提高模型的鲁棒性吗?
最简单的方法就是将一个单词的embedding的平均值作为这个单词的表示。作者将这种模型称之为meanChar模型,也即先将单词表示为一个平均embedding的单词表示,然后在使用例如charCNN模型的字级编码器。
很显然,根据定义meanChar模型对字符乱置不再敏感,但是对其他类型的噪声(Key和Nat)仍然敏感。
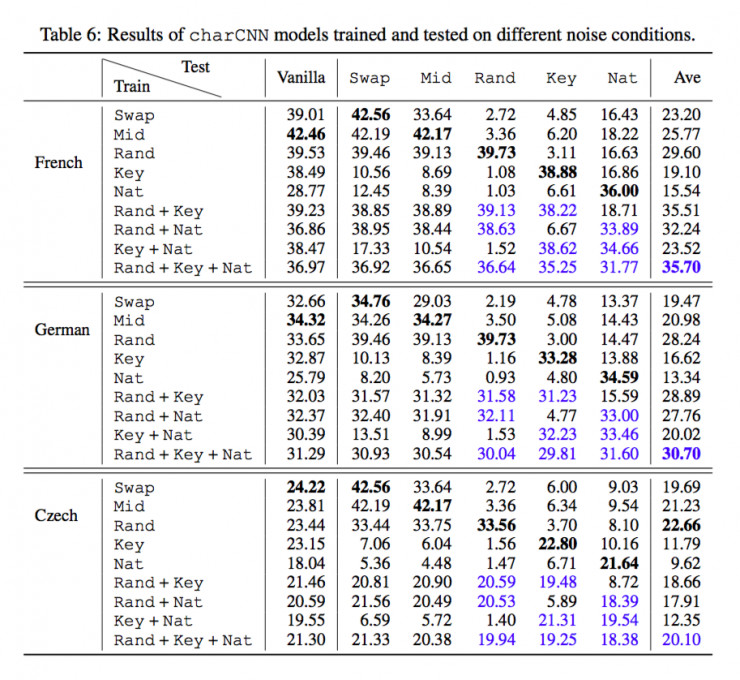
用Vanilla文本训练meanChar模型 ,然后用噪声文本测试(由于字符乱置不影响结果,将Swap、Mid、Rand合为Scr)。结果如下表第一行所示,可以看出的是,meanChar模型用在法语和德语中对Scrambled文本表现提高了7个百分点,但捷克语表现很糟糕,这可能是由于其语言复杂的形态。
2、黑箱对抗训练
为了提高模型的鲁棒性,作者采用了黑箱对抗训练的方法,也即用带噪声文本训练翻译模型。
首先用如上表,用噪声文本训练在某些语言(例如法语)上表现良好,但是其鲁棒性并不具有稳定的提高。这也很明显,meanChar模型并不一定能解决key或者Nat噪声的问题。
那么如果我们用更复杂的charCNN模型就会提高模型对不同种类噪声的鲁棒性吗?作者将用于训练的Scr文本拆开来训练模型——

发现:
1)尽管模型在不同的噪声下仍然表现不一,但整体平均的表现有所提升。
2)用Rand数据训练出的模型,对Swap和Mid文本测试结果都表现良好;而反之则不成立。这说明在训练数据中更多的噪声能够提高模型的鲁棒性。
3)只有用Nat数据集来训练,才能提高Nat数据集测试的鲁棒性。这个结果表明了计算模型和人类的表现之间的一个重要区别——在学习语言时,人类并没有明确地暴露在噪声样本中。
4)作者将三种噪声(Rand+Key+Nat)混合起来训练模型,发现虽然针对每一个样本的测试都表现略差,但整体上的鲁棒性却是最高的,而且对于多种噪声具有普遍性。
六、对结果的分析
从上面的结果可以看出,多种噪声同时训练charCNN的模型的鲁棒性更好。But why?
作者猜测可能是不同的卷积滤波器在不同种类的噪声中学到了鲁棒性。一个卷积滤波器原则上可以通过采用相等或接近相等的权重来捕获平均(或总和)的操作。
为了检验这个猜测,他们分析了分别用Rand数据和Rand+Key+Nat数据训练的两个charCNN模型学习到的权重。针对每个模型,他们计算了1000个过滤器中每一个过滤器维度上的方差,然后对这些变量做以平均。结果如下图

从图上可以看出,Rand模型学到的权重方差要远小于混合噪声模型学到的权重方差。换句话说,混合噪声训练的模型学习了更多不同的权重,除了平均表示(meanChar)外,还有助于捕捉形态属性。
而另一方面,混合噪声模型中方差的变化则较大,表明不同字符嵌入维度的滤波器之间存在较大的差异。相比之下Rand模型中方差的变化就接近零。
另一方面,我们还看到合成噪声训练的模型没有一个在Nat数据的测试中表现较好的。这表明自然噪声合成噪声有很大的不同。作者人工地检测了德语的Nat数据集中大约40个样本后,发现在Nat数据集中最常见的噪声来源是语言中的语音或音韵错误(34%)和字母遗漏(32%)。这些在合成噪声中并没有,所以这表明要生成更好合成噪声可能需要更多关于音素以及相应语言的知识。
七、总结
让我们来看一看用Rand+key+Nat的charCNN模型来翻译一下前面那个混乱的德语翻译的结果吧:
“According to a study of Cambridge University, it doesn't matter which technology in a word is going to get the letters in a word that is the only important thing for the first and last letter.”
当然,其实他们的结果并不完美,但非常值得借鉴。
如作者所说:“我们的目的有二:
1)作为一个开始,让大家去谈论神经网络翻译的鲁棒性训练和建模技巧;
2)促进大家去创造出更多更好的人工噪声,以应用到新的语言和任务中。